

Die Ära der generativen KI schreitet voran und eine Vielzahl von Unternehmen hat sich an der Entwicklung beteiligt.
Inmitten dieses KI-Booms haben viele Unternehmen ihre Modelle als „Open Source“ angepriesen, aber was bedeutet das in der Praxis wirklich?
Das Konzept von Open Source hat seine Wurzeln in der Software-Entwicklungsgemeinschaft. Bei herkömmlicher Open-Source-Software ist der Quellcode frei zugänglich und kann von jedem eingesehen, verändert und weitergegeben werden.
Im Wesentlichen ist Open Source ein gemeinschaftlicher Wissensaustausch, der durch Software-Innovationen vorangetrieben wird und zu Entwicklungen wie dem Linux-Betriebssystem, dem Firefox-Webbrowser und der Programmiersprache Python geführt hat.
Die Anwendung des Open-Source-Gedankens auf die heutigen massiven KI-Modelle ist jedoch alles andere als einfach.
Diese Systeme werden oft auf riesigen Datensätzen mit Terabytes oder Petabytes an Daten trainiert und verwenden komplexe neuronale Netzwerkarchitekturen mit Milliarden von Parametern.
Die erforderlichen Rechenressourcen kosten Millionen von Dollar, die Talente sind knapp und das geistige Eigentum ist oft gut geschützt.
Das können wir bei OpenAI beobachten, einem ehemaligen KI-Forschungslabor, das sich weitgehend dem Open-Source-Ethos verschrieben hat.
Dieser Ethos ging jedoch schnell verloren, als das Unternehmen das Geld roch und Investitionen anziehen musste, um seine Ziele zu erreichen.
Warum? Weil Open-Source-Produkte nicht auf Profit ausgerichtet sind und KI teuer und wertvoll ist.
Mit dem explosionsartigen Anstieg der generativen KI veröffentlichen Unternehmen wie Mistral, Meta, BLOOM und xAI Open-Source-Modelle, um die Forschung voranzutreiben und gleichzeitig zu verhindern, dass Unternehmen wie Microsoft und Google zu viel Macht an sich reißen.
Aber wie viele dieser Modelle sind wirklich quelloffen, und zwar nicht nur dem Namen nach?
Klären, wie offen Open-Source-Modelle wirklich sind
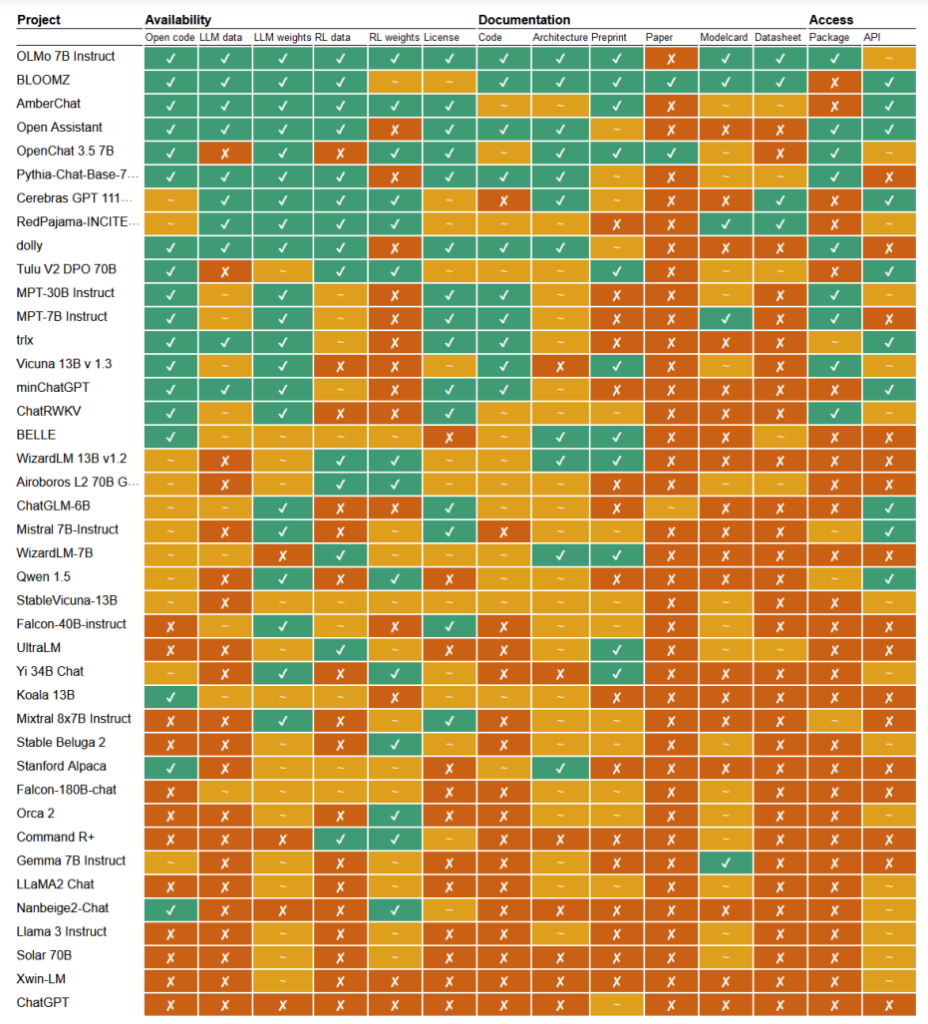
In einer kürzlich erschienenen Studiehaben die Forscher Mark Dingemanse und Andreas Liesenfeld von der Radboud Universität in den Niederlanden zahlreiche bekannte KI-Modelle analysiert, um zu untersuchen, wie offen sie sind. Sie untersuchten mehrere Kriterien, wie z. B. die Verfügbarkeit von Quellcode, Trainingsdaten, Modellgewichten, Forschungsarbeiten und APIs.
Das LLaMA-Modell von Meta und das Gemma-Modell von Google wurden beispielsweise als einfach „offen gewichtet“ eingestuft – das bedeutet, dass das trainierte Modell öffentlich zur Nutzung freigegeben wird, ohne dass vollständige Transparenz über den Code, den Trainingsprozess, die Daten und die Feinabstimmungsmethoden besteht.
Am anderen Ende des Spektrums heben die Forscher BLOOM hervor, ein großes mehrsprachiges Modell, das in Zusammenarbeit mit über 1.000 Forschern weltweit entwickelt wurde und ein Beispiel für echte Open-Source-KI darstellt. Jedes Element des Modells ist für die Überprüfung und weitere Forschung frei zugänglich.
In der Studie wurden mehr als 30 Modelle (sowohl Text- als auch Bildmodelle) bewertet, die jedoch zeigen, wie groß die Unterschiede zwischen den Modellen sind, die sich als Open-Source-Modelle bezeichnen:
- BloomZ (BigScience): Vollständig offen in Bezug auf alle Kriterien, einschließlich Code, Trainingsdaten, Modellgewichte, Forschungsunterlagen und API. Hervorgehoben als ein Beispiel für echte Open-Source-KI.
- OLMo (Allen Institute for AI): Offener Code, Trainingsdaten, Gewichte und Forschungsunterlagen. API nur teilweise offen.
- Mistral 7B-Instruct (Mistral AI): Offene Modellgewichte und API. Code und Forschungsunterlagen nur teilweise offen. Trainingsdaten sind nicht verfügbar.
- Orca 2 (Microsoft): Teilweise offene Modellgewichte und Forschungspapiere. Code, Trainingsdaten und API geschlossen.
- Gemma 7B unterrichten (Google): Teilweise offener Code und Gewichte. Trainingsdaten, Forschungspapiere und API geschlossen. Wird von Google als „offen“ und nicht als „Open Source“ bezeichnet.
- Llama 3 Unterweisung (Meta): Teilweise offene Gewichte. Code, Trainingsdaten, Forschungspapiere und API geschlossen. Ein Beispiel für ein „offenes Gewichtsmodell“ ohne größere Transparenz.
Ein Mangel an Transparenz
Die mangelnde Transparenz bei KI-Modellen, insbesondere bei denen, die von großen Technologieunternehmen entwickelt werden, gibt Anlass zu ernsthaften Bedenken hinsichtlich der Rechenschaftspflicht und der Aufsicht.
Ohne vollständigen Zugang zum Code des Modells, zu den Trainingsdaten und anderen wichtigen Komponenten ist es äußerst schwierig zu verstehen, wie diese Modelle funktionieren und Entscheidungen treffen. Das macht es schwierig, mögliche Verzerrungen, Fehler oder den Missbrauch von urheberrechtlich geschütztem Material zu erkennen und zu beheben.
Urheberrechtsverletzungen in KI-Trainingsdaten sind ein Paradebeispiel für die Probleme, die sich aus diesem Mangel an Transparenz ergeben. Viele proprietäre KI-Modelle, wie GPT-3.5/4/40/Claude 3/Gemini, wurden wahrscheinlich auf urheberrechtlich geschütztem Material trainiert.
Da die Trainingsdaten jedoch unter Verschluss gehalten werden, ist es fast unmöglich, bestimmte Daten innerhalb dieses Materials zu identifizieren.
Die jüngste Klage der New York Times gegen OpenAI zeigt, welche Folgen diese Herausforderung in der Praxis hat. OpenAI beschuldigte die NYT, mit Prompt-Engineering-Angriffen Trainingsdaten offenzulegen und ChatGPT dazu zu bringen, ihre Artikel wortwörtlich zu reproduzieren, um so zu beweisen, dass die Trainingsdaten von OpenAI urheberrechtlich geschütztes Material enthalten.
„Die Times hat jemanden dafür bezahlt, die Produkte von OpenAI zu hacken“, erklärte OpenAI.
Ian Crosby, der leitende Rechtsbeistand der NYT, antwortete: „Was OpenAI bizarrerweise als ‚Hacking‘ bezeichnet, ist einfach die Verwendung der Produkte von OpenAI, um nach Beweisen dafür zu suchen, dass sie die urheberrechtlich geschützten Werke der Times gestohlen und reproduziert haben. Und das ist genau das, was wir gefunden haben.
Dies ist nur ein Beispiel aus einem riesigen Stapel von Klagen, die derzeit zum Teil aufgrund der undurchsichtigen, undurchdringlichen Natur von KI-Modellen blockiert werden.
Dies ist nur die Spitze des Eisbergs. Ohne solide Transparenz und Maßnahmen zur Rechenschaftspflicht riskieren wir eine Zukunft, in der unerklärliche KI-Systeme Entscheidungen treffen, die unser Leben, unsere Wirtschaft und unsere Gesellschaft tiefgreifend beeinflussen, aber von der Kontrolle abgeschirmt bleiben.
Rufe nach Offenheit
Unternehmen wie Google und OpenAI wurden aufgefordert, ihre Zugang zu den inneren Abläufen ihrer Modelle zu gewähren für die Zwecke der Sicherheitsbewertung.
Die Wahrheit ist jedoch, dass selbst KI-Unternehmen nicht wirklich verstehen, wie ihre Modelle funktionieren.
Dies wird als „Blackbox“-Problem bezeichnet, das auftritt, wenn man versucht, die spezifischen Entscheidungen des Modells auf eine für den Menschen verständliche Weise zu interpretieren und zu erklären.
Ein Entwickler weiß zum Beispiel, dass ein Deep-Learning-Modell genau ist und gute Leistungen erbringt, aber er kann nicht genau sagen, welche Merkmale das Modell für seine Entscheidungen verwendet.
Anthropic, das die Claude-Modelle entwickelt hat, hat kürzlich ein Experiment durchgeführt durch, um herauszufinden, wie Claude 3 Sonnet funktioniert, und erklärt: „Wir behandeln KI-Modelle meist als Blackbox: Wir geben etwas ein und erhalten eine Antwort, ohne dass klar ist, warum das Modell gerade diese Antwort gibt und nicht eine andere. Das macht es schwer, darauf zu vertrauen, dass diese Modelle sicher sind: Wenn wir nicht wissen, wie sie funktionieren, woher wissen wir dann, dass sie keine schädlichen, voreingenommenen, unwahren oder anderweitig gefährlichen Antworten geben werden? Wie können wir darauf vertrauen, dass sie sicher und verlässlich sind?“
Dieses Experiment verdeutlicht, dass KI-Entwickler die Blackbox ihrer KI-Modelle nicht vollständig verstehen und dass es eine äußerst schwierige Aufgabe ist, die Ergebnisse objektiv zu erklären.
Anthropic schätzte sogar, dass es mehr Rechenleistung benötigt, um die Blackbox zu öffnen, als um das Modell selbst zu trainieren!
Entwickler versuchen, das Blackbox-Problem aktiv zu bekämpfen, z. B. durch Forschung wie „Explainable AI“ (XAI), die darauf abzielt, Techniken und Werkzeuge zu entwickeln, um KI-Modelle transparenter und interpretierbar zu machen.
XAI-Methoden versuchen, Einblicke in den Entscheidungsprozess des Modells zu geben, die einflussreichsten Merkmale hervorzuheben und für Menschen verständliche Erklärungen zu erstellen. XAI wurde bereits auf Modelle angewandt, die in wichtigen Bereichen wie der Arzneimittelentwicklung eingesetzt werden, wo das Verständnis der Funktionsweise eines Modells entscheidend für die Sicherheit sein kann.
Open-Source-Initiativen sind für XAI und andere Forschungen, die versuchen, die Blackbox zu durchdringen und KI-Modelle transparent zu machen, unerlässlich.
Ohne Zugang zum Code des Modells, zu den Trainingsdaten und anderen Schlüsselkomponenten können Forscher/innen keine Techniken entwickeln und testen, die erklären, wie KI-Systeme wirklich funktionieren, und die spezifischen Daten identifizieren, mit denen sie trainiert wurden.
Vorschriften könnten die Open-Source-Situation weiter verwirren
Die von der Europäischen Union kürzlich verabschiedete KI-Gesetz wird neue Vorschriften für KI-Systeme einführen, die sich speziell an Open-Source-Modelle richten.
Das Gesetz sieht vor, dass Open-Source-Allzweckmodelle bis zu einer bestimmten Größe von den umfangreichen Transparenzanforderungen ausgenommen werden.
Wie Dingemanse und Liesenfeld in ihrer Studie betonen, ist die genaue Definition von „Open-Source-KI“ im Rahmen des KI-Gesetzes jedoch noch unklar und könnte zu einem Streitpunkt werden.
Das Gesetz definiert Open-Source-Modelle derzeit als solche, die unter einer „freien und offenen“ Lizenz veröffentlicht werden, die es den Nutzern erlaubt, das Modell zu verändern. Es enthält jedoch keine Bestimmungen über den Zugang zu Trainingsdaten oder anderen wichtigen Komponenten.
Diese Unklarheit lässt Raum für Interpretationen und potenzielle Lobbyarbeit von Unternehmensinteressen. Die Forscher warnen davor, dass die Verfeinerung der Open-Source-Definition im KI-Gesetz „wahrscheinlich einen einzigen Druckpunkt bilden wird, auf den Konzernlobbys und große Unternehmen abzielen werden“.
Es besteht die Gefahr, dass ohne klare, robuste Kriterien dafür, was wirklich quelloffene KI ist, die Vorschriften unbeabsichtigt Schlupflöcher oder Anreize für Unternehmen schaffen könnten, die „Open-Washing“ betreiben – die Offenheit für sich in Anspruch nehmen, um rechtliche und öffentlichkeitswirksame Vorteile zu erlangen, während sie wichtige Aspekte ihrer Modelle weiterhin proprietär halten.
Außerdem könnte die globale Natur der KI-Entwicklung dazu führen, dass unterschiedliche Regelungen in den verschiedenen Ländern die Landschaft noch komplizierter machen.
Wenn große KI-Produzenten wie die USA und China unterschiedliche Ansätze in Bezug auf Offenheit und Transparenzanforderungen verfolgen, könnte dies zu einem fragmentierten Ökosystem führen, in dem der Grad der Offenheit je nach Herkunftsland eines Modells sehr unterschiedlich ist.
Die Autoren der Studie betonen, dass die Regulierungsbehörden eng mit der wissenschaftlichen Gemeinschaft und anderen Interessengruppen zusammenarbeiten müssen, um sicherzustellen, dass alle Open-Source-Bestimmungen in der KI-Gesetzgebung auf einem tiefen Verständnis der Technologie und der Grundsätze der Offenheit beruhen.
Dingemanse und Liesenfeld schlussfolgern in einem Diskussion mit Nature„Man kann mit Fug und Recht behaupten, dass der Begriff Open Source in den Ländern, die unter das EU-KI-Gesetz fallen, ein noch nie dagewesenes rechtliches Gewicht bekommen wird.“
Wie sich dies in der Praxis auswirkt, wird erhebliche Auswirkungen auf die zukünftige Richtung der KI-Forschung und -Einführung haben.







